


































![A Look at 30 Key Cyber Crime Statistics [2023 Data Update]](https://www.thesslstore.com/blog/wp-content/uploads/2022/02/cyber-crime-statistics-feature2-75x94.jpg)




 (No Ratings Yet)
(No Ratings Yet)New Browser Hack Lets Sites Track You Via Favicons
This New Kind of “Supercookie” Works Even if You’re in Incognito Mode, on a VPN, or Have Flushed Your Cache
How many tabs do you have open right now? Whether at work or at home, it’s become normal for most of us to be overloaded with tabs. And what’s the common thing with all of them, which helps us quickly identify which is which? That’s right – favicons. But what at first glance appears to be just a harmless little picture now has the potential to be an unstoppable tracking vector.

Researchers from the University of Illinois, Chicago have recently discovered a way to use favicons as a tracking device, suddenly transforming them into a security and/or privacy vulnerability. Websites can now theoretically track your footprints online, regardless of whether or not you’re taking the traditional steps to keep your activity private. We’re talking about a way of tracking that circumvents browser incognito modes, VPN connections, and cache flushing/deleting cookies.
So, what is the favicon tracking method and how does it work? What browsers are susceptible to the vulnerability? And how can you prevent this sort of tracking as you’re surfing the web?
Let’s hash it out.
How Do Favicons Work
You’re probably aware of the basics of what favicons are and how they work. They’re tiny image files, usually 16×16 or 32×32 pixels, that are used for site identification purposes on browser tabs. Usually, the favicon is the logo of the site or company, and you no doubt instantly recognize the more common ones like Google, Twitter, Facebook, etc. They’re there to make it easy to quickly identify sites and aid with keeping everything straight while browsing.
For a favicon to be displayed, there needs to be a particular attribute called out in the site’s header. When the tag is there, the browser calls for a specific icon file. The favicon gets displayed if the server returns an icon file that can be rendered properly. If not, a blank icon is displayed. The code itself looks similar to the following:

Favicons get cached by the browser and are kept separately from other cached items like images, HTML files, and CSS style sheets. When you clear the cache in your browser, you’re deleting all those items EXCEPT for the favicons. They will remain and can be accessed from incognito mode or private browsing sessions, as well.
The storage area for favicons is appropriately called the “f-cache.” Jonas Strehle, a German software developer and researcher who built on the initial work done by those at the University of Illinois, explains how
The favicons must be made very easily accessible by the browser. Therefore, they are cached in a separate local database on the system, called the favicon cache (F-Cache). When a user visits a website, the browser checks if a favicon is needed by looking up the source of the shortcut icon link reference of the requested webpage. The browser initially checks the local F-cache for an entry containing the URL of the active website. If a favicon entry exists, the icon will be loaded from the cache and then displayed. However, if there is no entry, for example because no favicon has ever been loaded under this particular domain, or the data in the cache is out of date, the browser makes a GET request to the server to load the site’s favicon.
These f-cache entries end up containing detailed data regarding your browsing history, even though in the end they’re merely used to display a tiny little image file. This mini-database stores information such as the URL you visited, the favicon ID, and the time-to-live (TTL). You can see an example of f-cache data below:

How Favicon Tracking Works
The concept of favicon tracking takes advantage of the fact that favicons themselves are stored in their own separate location. Because of this, sites can use favicons to serve as an identifier for individual users that will continue to function over the long term.
As far as tracking goes, one favicon isn’t enough to identify someone. However, if multiple favicons are deployed in the favicon cache by a website, they can be used to create a sort of “fingerprint” for any given user by leveraging both the favicons themselves and the data in the f-cache. This data cannot be easily cleared by the user, and the tracking ID will remain even if ad blockers or VPNs are used, incognito mode is turned on, or the cache is flushed.
That’s the theory that the University of Illinois researchers came up with, but then Strehle took it a step further after reading their paper and turned it into reality. He calls his method the “Supercookie,” and explains how it works:
By combining the state of delivered and not delivered favicons for specific URL paths for a browser, a unique pattern (identification number) can be assigned to the client. When the website is reloaded, the web server can reconstruct the identification number with the network requests sent by the client for the missing favicons and thus identify the browser.
Basically, a server can figure out whether or not a favicon has already been loaded by the browser. If it’s already in the f-cache, the browser will load it and the server doesn’t have to do anything else. If it’s not in the f-cache, the browser will send a request to the server for the favicon and the server will send the favicon back. Seems like a simple and innocent process, right?
However, by combining the statuses of present and non-present favicons, a website can create a unique ID for any given visitor. When the page is refreshed, the server can recreate the ID by looking at the favicon requests sent by the user’s browser and thus identify them.
Have a Second? Or Two, to Be Precise…
So how exactly are multiple favicons actually loaded? Doesn’t each page only display a single favicon? That’s correct, but this method gets around that by directing visitors to various subdomains, one after the other, that each have their own favicon. The page that was originally requested gets displayed at the end of the process.
The amount of redirections is in proportion to the number of unique users that need to be tracked. For example, if you wished to track 4.5 billion visitors, then you’d need 32 different redirections (each redirection equals 1 bit of entropy). As the University of Illinois research paper explains:
These subdomains serve different favicons and, thus, create their own entries in the Favicon-Cache. Accordingly, a set of N-subdomains can be used to create an N-bit identifier, that is unique for each browser. Since the attacker controls the website, they can force the browser to visit subdomains without any user interaction. In essence, the presence of the favicon for subdomain in the cache corresponds to a value of 1 for the i-th bit of the identifier, while the absence denotes a value of 0.
So again, it all comes down to checking if particular favicons are present or not on each subdomain. Of course, your site will suffer a speed hit with that many redirections – on the order of about 2 seconds for 32 of them – but there are adjustments that can be made to reduce the delay.
The good news is that so far, the Supercookie is more a proof-of-concept than anything else, and nothing of its kind has been seen out in the real world yet. Strehle has setup a demo website that employs the Supercookie method and shows the user how it works (don’t worry, it’s perfectly safe to visit). He’s been completely transparent regarding his work and has posted his source code online via Github along with a detailed explanation of the functionality.
Which Browsers Allow Favicon Tracking?
Favicon tracking currently works with Chrome, Edge, and Safari. Until recently it worked with Brave, but they have created and deployed a working countermeasure since the research paper was released. You can see the exact compatibility breakdown in the figures below:

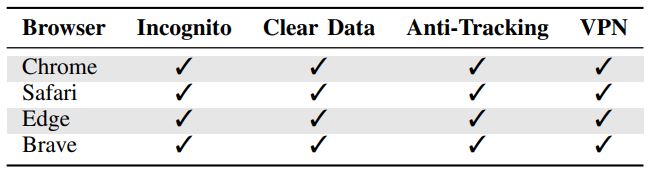
Ironically, a bug is preventing favicon tracking from working with Firefox. Per the research paper,
In fact, while monitoring the browser during the attack’s execution we observe that it has a valid favicon cache which creates appropriate entries for every visited page with the corresponding favicons. However, it never actually uses the cache to fetch the entries. As a result, Firefox actually issues requests to re-fetch favicons that are already present in the cache.
So basically, Firefox sends favicon requests no matter what, even if they are already present in the f-cache. This bug has been acknowledged by Mozilla. It will be interesting to see how they proceed, since “fixing” this issue will result in the favicon tracking method working with the browser unless other countermeasures are deployed.
How to Prevent Favicon Tracking
The concept of favicon tracking is so alarming because it sidesteps all the usual ways of staying private while surfing the web. Until the browsers implement effective mitigation measures, your best bet is to simply disable favicons in your browser. You can find out how to do so via the links below:
- Disabling favicons in Safari
- Disabling favicons in Edge
- In Chrome, you can’t fully disable favicons. The best you can do is to remove the favicon files, but this won’t prevent a site from tracking you with them.
A Fix is On The Way
Google has said that a fix is currently in progress for Chrome, and Apple has said similar for Safari. Microsoft hasn’t commented on the research yet, but one can assume that they will also tackle this issue sooner than later in order to keep up with the competition.
In the meantime, odds are you’ll be safe from this tracking method that is still in the proof-of-concept stage. Still, it’s a very interesting idea that illustrates just how easy it can be to turn safe, routine features into tools for the bad guys to use against you. It’s why you always want to have as many layers as possible to protect you – you never know where the next threat is going to come from!




5 Ways to Determine if a Website is Fake, Fraudulent, or a Scam – 2018
in Hashing Out Cyber SecurityHow to Fix ‘ERR_SSL_PROTOCOL_ERROR’ on Google Chrome
in Everything EncryptionRe-Hashed: How to Fix SSL Connection Errors on Android Phones
in Everything EncryptionCloud Security: 5 Serious Emerging Cloud Computing Threats to Avoid
in ssl certificatesThis is what happens when your SSL certificate expires
in Everything EncryptionRe-Hashed: Troubleshoot Firefox’s “Performing TLS Handshake” Message
in Hashing Out Cyber SecurityReport it Right: AMCA got hacked – Not Quest and LabCorp
in Hashing Out Cyber SecurityRe-Hashed: How to clear HSTS settings in Chrome and Firefox
in Everything EncryptionRe-Hashed: The Difference Between SHA-1, SHA-2 and SHA-256 Hash Algorithms
in Everything EncryptionThe Difference Between Root Certificates and Intermediate Certificates
in Everything EncryptionThe difference between Encryption, Hashing and Salting
in Everything EncryptionRe-Hashed: How To Disable Firefox Insecure Password Warnings
in Hashing Out Cyber SecurityCipher Suites: Ciphers, Algorithms and Negotiating Security Settings
in Everything EncryptionThe Ultimate Hacker Movies List for December 2020
in Hashing Out Cyber Security Monthly DigestAnatomy of a Scam: Work from home for Amazon
in Hashing Out Cyber SecurityThe Top 9 Cyber Security Threats That Will Ruin Your Day
in Hashing Out Cyber SecurityHow strong is 256-bit Encryption?
in Everything EncryptionRe-Hashed: How to Trust Manually Installed Root Certificates in iOS 10.3
in Everything EncryptionHow to View SSL Certificate Details in Chrome 56
in Industry LowdownPayPal Phishing Certificates Far More Prevalent Than Previously Thought
in Industry Lowdown