







































 (6 votes, average: 4.50 out of 5)
(6 votes, average: 4.50 out of 5)What Is a Hash Function in Cryptography? A Beginner’s Guide
This cryptographic tool aids secure authentication and ensures data message integrity across digital channels — here’s what to know about what a hash function is and how it works
What’s four letters and is both a tasty breakfast item as well as a plant with pointy leaves? If you guessed “hash,” then you’re right! But hash has another meaning as well that relates to cryptography, and that’s what we’re going to discuss here.
A hash function is a serious mathematical process that holds a critical role in public key cryptography. Why? Because it’s what helps you to:
- Securely store passwords in a database,
- Ensure data integrity (in a lot of different applications) by indicating when data has been altered,
- Make secure authentication possible, and
- Organize content and files in a way that increases efficiency.
You can find hash functions in use just about everywhere — from signing the software applications you use on your phone to securing the website connections you use to transmit sensitive information online. But what is a hash function in cryptography? What does it do exactly to help you protect your business’s data? And how does hashing work?
Let’s hash it out.
What Is a Hash Function?
A term like “hash function” can mean several things to different people depending on the context. For hash functions in cryptography, the definition is a bit more straightforward. A hash function is a unique identifier for any given piece of content. It’s also a process that takes plaintext data of any size and converts it into a unique ciphertext of a specific length.
The first part of the definition tells you that no two pieces of content will have the same hash digest, and if the content changes, the hash digest changes as well. Basically, hashing is a way to ensure that any data you send reaches your recipient in the same condition that it left you, completely intact and unaltered.
But, wait, doesn’t that sound a lot like encryption? Sure, they’re similar, but encryption and hashing are not the same thing. They’re two separate cryptographic functions that aid in facilitating secure, legitimate communications. So, if you hear someone talking about “decrypting” a hash value, then you know they don’t know what they’re talking about because, well, hashes aren’t encrypted in the first place.
We’ll speak more to the difference between these two processes a little later. But for now, let’s stick with the topic of hashing. So, what does hashing look like?
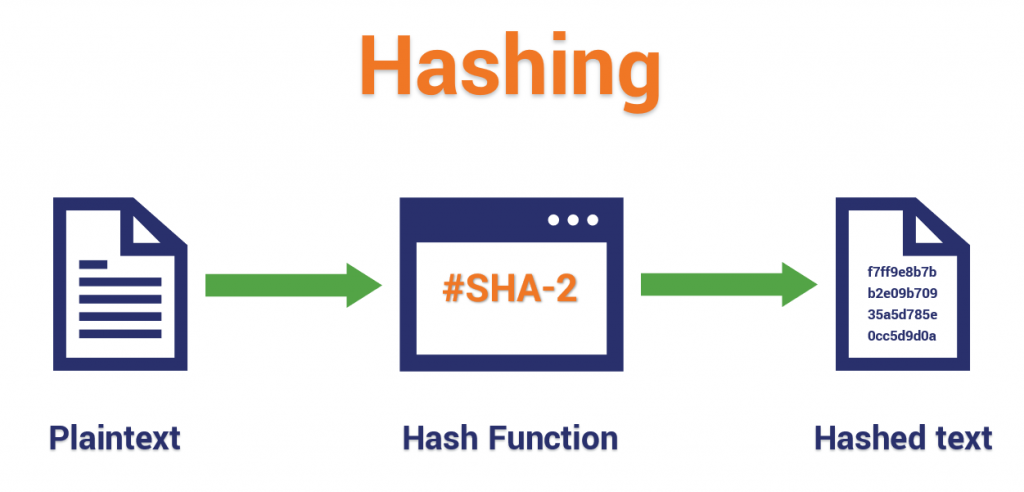
A simple illustration of what a hash function does by taking a plaintext data input and using a mathematical algorithm to generate an unreadable output.
Looks simple enough, right? But what happens under the surface of the hash function is where things get a lot more interesting (and complicated). Here’s a great video that helps to break hash functions down:
So, how do you define a hash in a more technical sense? A hash function is a versatile one-way cryptographic algorithm that maps an input of any size to a unique output of a fixed length of bits. The resulting output, which is known as a hash digest, hash value, or hash code, is the resulting unique identifier we mentioned earlier.
When you hash data, the resulting digest is typically smaller than the input that it started with. (Probably the exception here is when you’re hashing passwords.) With hashing, it doesn’t matter if you have a one-sentence message or an entire book — the result will still be a fixed-length chunk of bits (1s and 0s). This prevents unintended parties from figuring out how big (or small) the original input message was.
Hash functions are primarily used for authentication but also have other uses.
Are Hash Functions Reversible?
The answer isn’t quite as straightforward as you may think. A hash function is called a one-way function because of the computing power, time, and cost it would take to brute force it. In a cybercriminal’s perfect world, if they had the ideal computer, time, and resources at their disposal, there’s a possibility that they could brute force it. But in the real world, it’s virtually impossible.
The reality is that trying every possible combination leading to a hash value is entirely impractical. So, for all intents and purposes, a hash function is considered an irreversible, one-way function.
Properties of a Strong Hash Algorithm
So, what makes for a strong hashing algorithm? There are a few key traits that all good ones share:
- Determinism — A hash algorithm should be deterministic, meaning that it always gives you an output of identical size regardless of the size of the input you started with. This means that if you’re hashing a single sentence, the resulting output should be the same size as one you’d get when hashing an entire book.
- Pre-Image Resistance — The idea here is that a strong hash algorithm is one that’s preimage resistance, meaning that it’s infeasible to reverse a hash value to recover the original input plaintext message. Hence, the concept of hashes being irreversible, one-way functions.
- Collision Resistance — A collision occurs when two objects collide. Well, this concept carries over in cryptography with hash values. If two unique samples of input data result in identical outputs, it’s known as a collision. This is bad news and means that the algorithm you’re using to hash the data is broken and, therefore, insecure. Basically, the concern here is that someone could create a malicious file with an artificial hash value that matches a genuine (safe) file and pass it off as the real thing because the signature would match. So, a good and trustworthy hashing algorithm is one that is resistant to these collisions.
- Avalanche Effect — What this means is that any change made to an input, no matter how small, will result in a massive change in the output. Essentially, a small change (such as adding a comma) snowballs into something much larger, hence the term “avalanche effect.”
- Hash Speed — Hash algorithms should operate at a reasonable speed. In many situations, hashing algorithms should compute hash values quickly; this is considered an ideal property of a cryptographic hash function. However, this property is a little more subjective. You see, faster isn’t always better because the speed should depend on how the hashing algorithm is going to be used. Sometimes, you want a faster hashing algorithm, and other times it’s better to use a slower one that takes more time to run through. The former is better for website connections and the latter is better for password hashing.
What Does a Hash Function Do?
One purpose of a hash function in cryptography is to take a plaintext input and generate a hashed value output of a specific size in a way that can’t be reversed. But they do more than that from a 10,000-foot perspective. You see, hash functions tend to wear a few hats in the world of cryptography. In a nutshell, strong hash functions:
- Ensure data integrity,
- Secure against unauthorized modifications,
- Protect stored passwords, and
- Operate at different speeds to suit different purposes.
Ensure Data Integrity
Hash functions are a way to ensure data integrity in public key cryptography. What I mean by that is that hash functions serve as a check-sum, or a way for someone to identify whether data has been tampered with after it’s been signed. It also serves as a means of identity verification.
For example, let’s say you’ve logged on to public Wi-Fi to send me an email. (Don’t do that, by the way. It’s very insecure.) So, you write out the message, sign it using your digital certificate, and send it on its way across the internet. This is what you might call prime man-in-the-middle attack territory — meaning that someone could easily intercept your message (again, because public wireless networks are notoriously insecure) and modify it to suit their evil purposes.
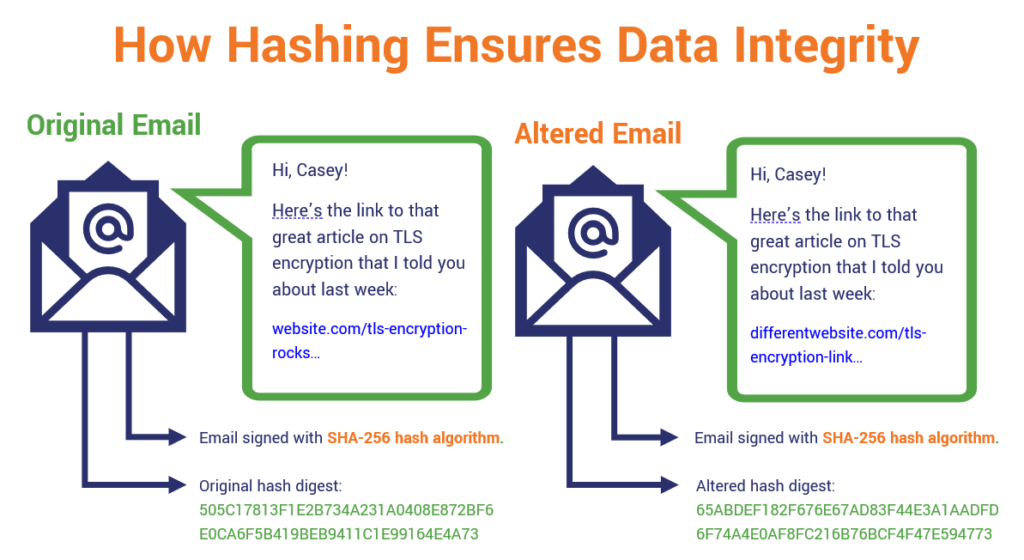
So, now I receive the message and I want to know it’s legitimate. What I can do then is use the hash value your digital signature provides (along with the algorithm it tells me you used) to re-generate the hash myself to verify whether the hash value I create matches the one you sent. If it matches, great, it means that no one has messed with it. But if it doesn’t… well, metaphoric klaxons sound, red flags go up, and I know to not trust it.
Even if something tiny changed in a message — you capitalize a letter instead of using one that’s lowercase, or you swap an exclamation mark where there was a period — it’s going to result in the generation of an entirely new hash value. But that’s the whole idea here — no matter how big or small a change, the difference in hash values will tell you that it isn’t legitimate.
Secure Against Unauthorized Modifications
One of the best aspects of a cryptographic hash function is that it helps you to ensure data integrity. But if you apply a hash to data, does it mean that the message can’t be altered? No. But what it does is inform the message recipient that the message has been changed. That’s because even the smallest of changes to a message will result in the creation of an entirely new hash value.
Think of hashing kind of like you would a smoke alarm. While a smoke alarm doesn’t stop a fire from starting, it does let you know that there’s danger before it’s too late.
Enable You to Verify and Securely Store Passwords
Nowadays, many websites allow you to store your passwords so you don’t have to remember them every time you want to log in. But storing plaintext passwords like that in a public-facing server would be dangerous because it leaves that information vulnerable to cybercriminals. So, what websites typically do is hash passwords to generate hash values, which is what they store instead.
But password hashes on their own isn’t enough to protect you against certain types of attacks, including brute force attacks. This is why you first need to add a salt. A salt is a unique, random number that’s applied to plaintext passwords before they’re hashed. This provides an additional layer of security and can protect passwords from password cracking methods like rainbow table attacks. (Keep an eye out for our future article on rainbow tables in the next few weeks.)
Operate at Different Speeds, Suiting Different Purposes
It’s also important to note that hash functions aren’t one-size-fits-all tools. As we mentioned earlier, different hash functions serve different purposes depending on their design and hash speeds. They work at different operational speeds — some are faster while others are much slower. These speeds can aid or impede the security of a hashing algorithm depending on how you’re using it. So, some fall under the umbrella of secure hashing algorithms while others do not.
An example of where you’d want to use a fast hashing algorithm is when establishing secure connections to websites. This is an example of when having a faster speed matters because it helps to provide a better user experience. However, if you were trying to enable your websites to store passwords for your customers, then you’d definitely want to use a slow hashing algorithm. At scale, this would require a password-cracking attack (such as brute force) that takes up more time and computing resources for cybercriminals. You don’t want to make it easy for them, right?
Where You’ll Find Hashes in Use
But where do you find hash functions? Look no further than the technology surrounding you. Hashing is useful for everything from signing new software and verifying digital signatures to securing the website connections in your computer and mobile web browsers. It’s also great for indexing and retrieving items in online databases. For example, hashing is used for verifying:
- Data blocks in cryptocurrencies and other blockchain technologies.
- Data integrity of software, emails, and documents.
- Passwords and storing password hashes (rather than the passwords themselves) in online databases. (Note: This process requires a little “dash” of something special to make those hashes more secure — a salt).
Hash functions can be found throughout public key cryptography. For example, you’ll find hash functions are facilitated through the use of:
- SSL/TLS certificates (i.e., website security certificates),
- Code signing certificates,
- Document signing certificates, and
- Email signing certificates.
How Does Hashing Work?
When you hash a message, you take a string of data of any size as your input, run it through a mathematical algorithm that results in the generation of an output of a fixed length.
In some methods of hashing, that original data input is broken up into smaller blocks of equal size. If there isn’t enough data in any of the blocks for it to be the same size, then padding (1s and 0s) can be used to fill it out. Then those individual blocks of data are run through a hashing algorithm and result in an output of a hash value. The process looks something like this:
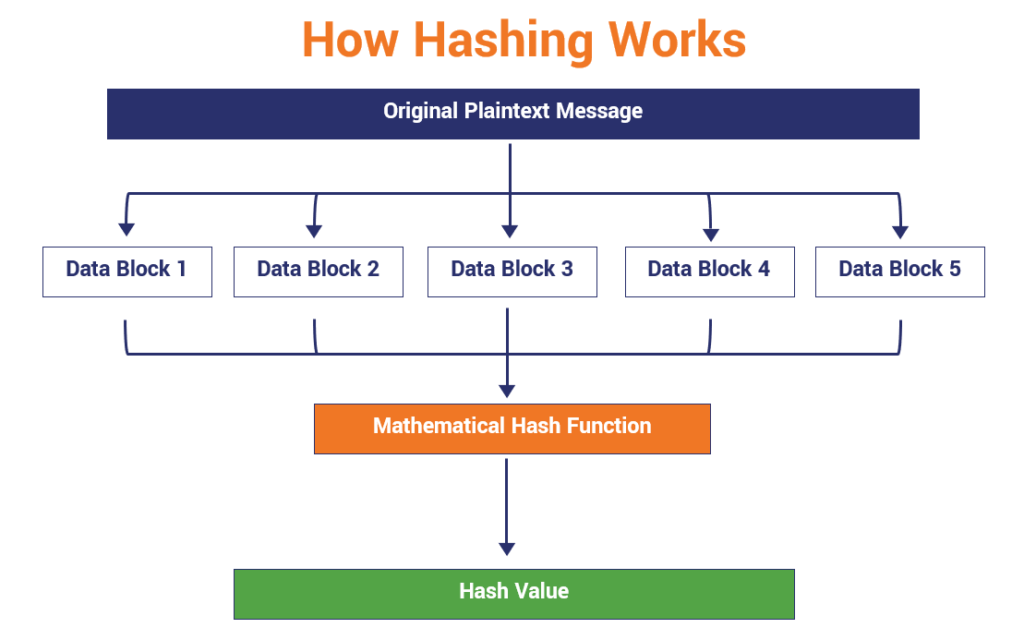
Of course, this process would look a bit different if you were hashing passwords for storage in an online server. That process would involve the use of a salt. Basically, you’d add a unique, random value to the message before running it through the hashing algorithm. By even just adding a single character, then you get an entirely new hash value at the end of the process.
Hashing Examples with Different Algorithms
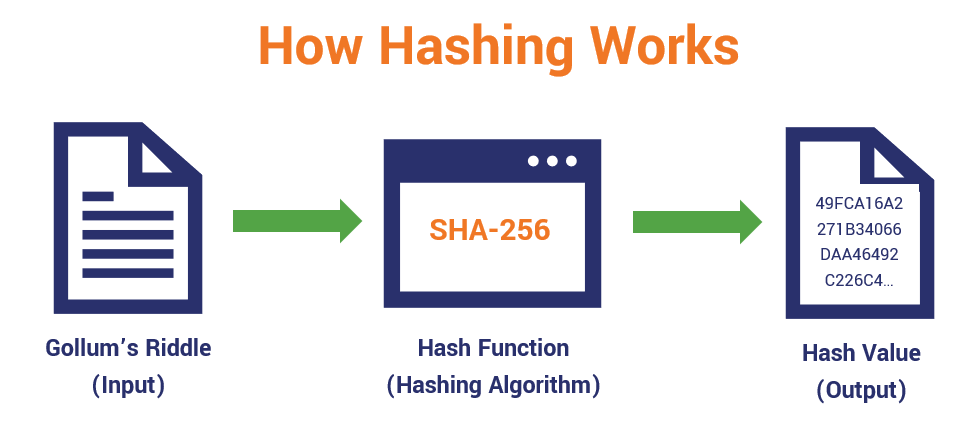
Okay, now that we know what a hash function is and what it does in a theoretical context, let’s consider how it works logistically with a few examples. Let’s say you have the following riddle from Gollum in The Hobbit as your input:
“It cannot be seen, cannot be felt,
Cannot be heard, cannot be smelt.
It lies behind stars and under hills,
And empty holes it fills.
It comes out first and follows after,
Ends life, kills laughter.”
No, I’m not going to give you the answer to the riddle if you haven’t already figured it out. But if you were to run that riddle through a SHA-256 hashing algorithm, the resulting output would look like this on your screen:
49FCA16A2271B34066DAA46492C226C4D4F61D56452A1E1A01A3201B234509A2
And here is an illustration that shows how we get from A to B:
What if you also decide to hash a smaller message? Say, for example, “The Lord of the Rings.” Then your output would look the same in terms of size (as shown below) so long as you use the same hashing algorithm:
01912B8E8425CFF006F430C15DBC4991F1799401F7B6BEB0633E56529FE148B9
That’s because both example strings are 256 bits, which display on your screen as 64 hexadecimal characters per string. No matter how large or how small the message, it’s always going to return an output that is the same size. Remember, hash algorithms are deterministic, so this means that they always result in the same size output regardless of the size of the input.
Now, if you were to take the same six-line riddle input and run it through an MD5 hash function, then you’d wind up with a hash value that looks something like this instead:
B53CE8A3139752B10AAE878A15216598
As you can see, the output is quite a bit shorter. That’s because MD5 gives you a hash digest that’s only 32 hexadecimal characters long. It’s literally half the size of the digests that result from a SHA-256 hashing algorithm. But every time you run an MD5 hashing algorithm on a plaintext message, the resulting output will be the same size.
What if you decided to run the riddle through a SHA-512 hashing algorithm? Then we go to the opposite end of the spectrum in terms of length and your digest would look something like this (a 512-bit hexadecimal string):
6DC1AAE5D80E8F72E5AF3E88A5C0FA8A71604739D4C0618182303EEEB1F02A0DBA319987D5B5F717E771B9DA1EAD7F3F92DC8BA48C064D41DD790D69D7D98B44
Hash vs Encryption
But aren’t hashing and encryption the same thing? Nope. Yes, they’re both cryptography functions that use algorithms as a part of their processes. But that’s just about where the similarities end. We covered the differences between hashing and encryption in another article, so we aren’t going to rehash all of that here.
As you now know, a hash function is a one-way function. The idea is that you can use it to convert readable plaintext data into an unreadable hexadecimal string of digits but not the other way around. Encryption, on the other hand, is known as a two-way function. That’s because the whole point of being able to encrypt something is to prevent unauthorized or unintended parties from accessing the data. So, you encrypt data so that it can only be decrypted by the person who has the key.
Examples of Common Hashing Algorithms & Families of Algorithms
Okay, we now know what hash functions are and how hashing algorithms work. Now it’s time to learn what some of the most common hash algorithms are. NIST provides guidance on hash functions as do several Federal Information Processing Standards (FIPS).
A few examples of common hashing algorithms include:
- Secure Hash Algorithm (SHA) — This family of hashes contains SHA-1, SHA-2 (a family within a family that includes SHA-224, SHA-256, SHA-384, and SHA-512), and SHA-3 (SHA3-224, SHA3-256, SHA3-384, and SHA3-512). SHA-1 has been deprecated and the most commonly hashing algorithm now is SHA-256.
- Message Digest (MD) — This family of hashes contains a variety of hash functions that include MD2, MD4, MD5, and MD6. MD5 was long considered a go-to hashing algorithm but it’s now considered broken because it results in collisions in the wild.
- Windows NTHash — Also known as a Unicode hash or NTLM, this hash is commonly used by Windows systems because it’s more secure than its predecessor, LM hash. However, NTHash also still has vulnerabilities to worry about as well, but this particular algorithm is integral to Windows systems. While the use of NTLMv1 is pretty much frowned upon nowadays, NTLM2 is something that’s still in use.
Other examples of hash algorithms includeBLAKE 2 and BLAKE 3, RIPEMD-160, and WHIRLPOOL, among others.
What We Hashed Out (TL;DR)
There’s a lot to know about hash functions and hashing in general. What they are, what they do, how they operate, and where you’ll find them in use in computer communications and technologies.
- Hashing is useful in data structure for indexing and retrieving dataset items. It also enables verification by detecting modifications.
- In cryptography, hashing takes plaintext data (input) and runs is through a mathematical process known as a hashing algorithm. This process generates an output, called a hash value, of a fixed length.
- A hash function is deterministic, meaning that, regardless of the size of the input, the output will always be the same size. It’s also collision and preimage resistant.
- Collision resistance means that you can’t have two unique inputs resulting in the same output, and
- Preimage resistance refers to a hash being a one-way function that can’t be reversed to uncover the original plaintext message. For all intents and purposes, hash functions are not reversible.
- You can’t manipulate data or make even tiny changes without entirely changing the resulting hash value. This is known as the avalanche effect.
- Different hashing algorithms — of which there are many families and individual algorithms — operate at different speeds and work on different sizes of data. For example, SHA-256 has an output of 256 bits (or what equates to a string of 64 hexadecimal characters).




5 Ways to Determine if a Website is Fake, Fraudulent, or a Scam – 2018
in Hashing Out Cyber SecurityHow to Fix ‘ERR_SSL_PROTOCOL_ERROR’ on Google Chrome
in Everything EncryptionRe-Hashed: How to Fix SSL Connection Errors on Android Phones
in Everything EncryptionCloud Security: 5 Serious Emerging Cloud Computing Threats to Avoid
in ssl certificatesThis is what happens when your SSL certificate expires
in Everything EncryptionRe-Hashed: Troubleshoot Firefox’s “Performing TLS Handshake” Message
in Hashing Out Cyber SecurityReport it Right: AMCA got hacked – Not Quest and LabCorp
in Hashing Out Cyber SecurityRe-Hashed: How to clear HSTS settings in Chrome and Firefox
in Everything EncryptionRe-Hashed: The Difference Between SHA-1, SHA-2 and SHA-256 Hash Algorithms
in Everything EncryptionThe Difference Between Root Certificates and Intermediate Certificates
in Everything EncryptionThe difference between Encryption, Hashing and Salting
in Everything EncryptionRe-Hashed: How To Disable Firefox Insecure Password Warnings
in Hashing Out Cyber SecurityCipher Suites: Ciphers, Algorithms and Negotiating Security Settings
in Everything EncryptionThe Ultimate Hacker Movies List for December 2020
in Hashing Out Cyber Security Monthly DigestAnatomy of a Scam: Work from home for Amazon
in Hashing Out Cyber SecurityThe Top 9 Cyber Security Threats That Will Ruin Your Day
in Hashing Out Cyber SecurityHow strong is 256-bit Encryption?
in Everything EncryptionRe-Hashed: How to Trust Manually Installed Root Certificates in iOS 10.3
in Everything EncryptionHow to View SSL Certificate Details in Chrome 56
in Industry LowdownA Call To Let’s Encrypt: Stop Issuing “PayPal” Certificates
in Industry Lowdown